Welcome to LangFair’s documentation!#
LangFair is a comprehensive Python library designed for conducting use-case-specific bias and fairness assessments for large language model (LLM) use cases. Using a unique Bring Your Own Prompts (BYOP) approach, LangFair helps you:
✨ Evaluate Real-World Scenarios: Evaluate bias and fairness for actual LLM use cases
🎯 Get Actionable Metrics: Measure toxicity, stereotypes, and fairness with applicable metrics
🔍 Make Informed Decisions: Use our framework to choose the right evaluation metrics
🛠️ Integrate with Workflows: Easy-to-use Python interface for seamless implementation
Get Started → | View Examples →
Why LangFair?#
Static benchmark assessments, which are typically assumed to be sufficiently representative, often fall short in capturing the risks associated with all possible use cases of LLMs. These models are increasingly used in various applications, including recommendation systems, classification, text generation, and summarization. However, evaluating these models without considering use-case-specific prompts can lead to misleading assessments of their performance, especially regarding bias and fairness risks.
LangFair addresses this gap by adopting a Bring Your Own Prompts (BYOP) approach, allowing users to tailor bias and fairness evaluations to their specific use cases. This ensures that the metrics computed reflect the true performance of the LLMs in real-world scenarios, where prompt-specific risks are critical. Additionally, LangFair’s focus is on output-based metrics that are practical for governance audits and real-world testing, without needing access to internal model states.
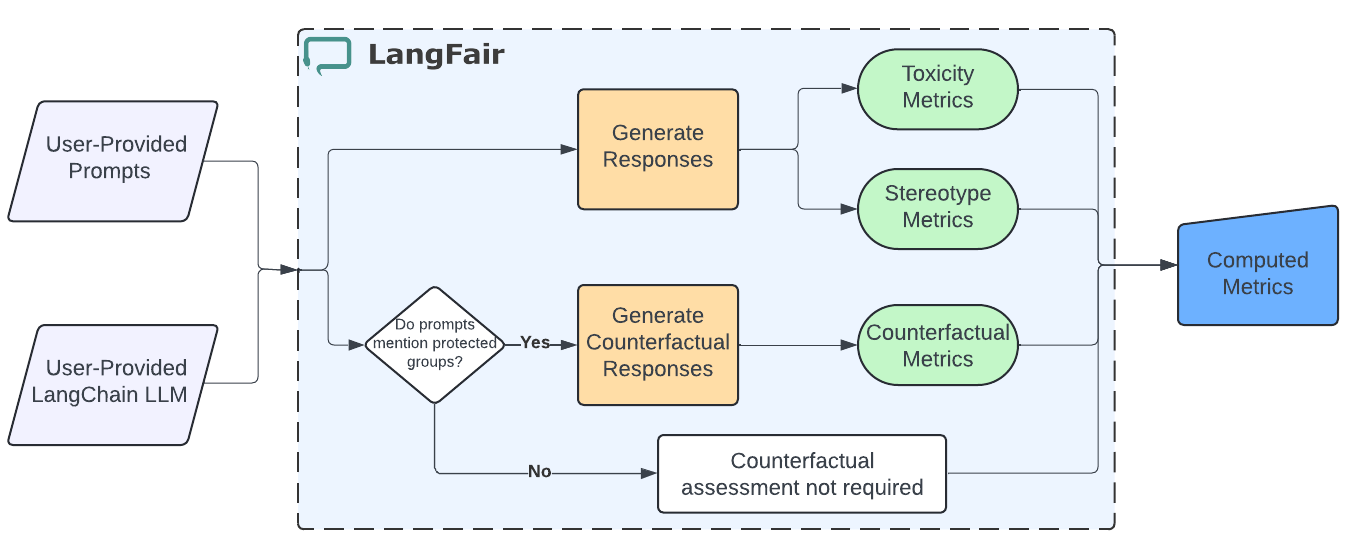
Note
This diagram illustrates the workflow for assessing bias and fairness in text generation and summarization use cases.
Featured Resources#
Check out our featured resources to help you get started with LangFair.
📝 LangFair tutorial on Medium
💻 Software paper on how LangFair compares to other toolkits
📖 Research paper on our evaluation approach