🎯 White-Box Uncertainty Quantification#
White-box Uncertainty Quantification (UQ) methods leverage token probabilities to estimate uncertainty. They are significantly faster and cheaper than black-box methods, but require access to the LLM’s internal probabilities, meaning they are not necessarily compatible with all LLMs/APIs. This demo provides an illustration of how to use state-of-the-art white-box UQ methods with uqlm. The following scorers are available:
Minimum token probability (Manakul et al., 2023)
Length-Normalized Joint Token Probability (Malinin & Gales, 2021)
📊 What You’ll Do in This Demo#
1
Set up LLM and prompts.
Set up LLM instance and load example data prompts.
2
Generate LLM Responses and Confidence Scores
Generate and score LLM responses to the example questions using the WhiteBoxUQ() class.
3
Evaluate Hallucination Detection Performance
Visualize model accuracy at different thresholds of the various white-box UQ confidence scores. Compute precision, recall, and F1-score of hallucination detection.
⚖️ Advantages & Limitations#
Pros
Minimal Latency Impact: Token probabilities are already returned by the LLM.
No Added Cost: Doesn’t require additional LLM calls.
Cons
Limited Compatibility: Requires access to token probabilities, not available for all LLMs/APIs.
[2]:
import os
import numpy as np
from sklearn.metrics import precision_score, recall_score, f1_score
from uqlm import WhiteBoxUQ
from uqlm.utils import load_example_dataset, math_postprocessor, plot_model_accuracies, Tuner
## 1. Set up LLM and Prompts
In this demo, we will illustrate this approach using a set of math questions from the GSM8K benchmark. To implement with your use case, simply replace the example prompts with your data.
[3]:
# Load example dataset (gsm8k)
gsm8k = load_example_dataset("gsm8k", n=100)
gsm8k.head()
Loading dataset - gsm8k...
Processing dataset...
Dataset ready!
[3]:
| question | answer | |
|---|---|---|
| 0 | Natalia sold clips to 48 of her friends in Apr... | 72 |
| 1 | Weng earns $12 an hour for babysitting. Yester... | 10 |
| 2 | Betty is saving money for a new wallet which c... | 5 |
| 3 | Julie is reading a 120-page book. Yesterday, s... | 42 |
| 4 | James writes a 3-page letter to 2 different fr... | 624 |
[5]:
# Define prompts
MATH_INSTRUCTION = "When you solve this math problem only return the answer with no additional text.\n"
prompts = [MATH_INSTRUCTION + prompt for prompt in gsm8k.question]
In this example, we use AzureChatOpenAI to instantiate our LLM, but any LangChain Chat Model may be used. Be sure to replace with your LLM of choice.
[6]:
# import sys
# !{sys.executable} -m pip install python-dotenv
# !{sys.executable} -m pip install langchain-openai
# # User to populate .env file with API credentials
from dotenv import load_dotenv, find_dotenv
from langchain_openai import AzureChatOpenAI
load_dotenv(find_dotenv())
llm = AzureChatOpenAI(
deployment_name=os.getenv("DEPLOYMENT_NAME"),
openai_api_key=os.getenv("API_KEY"),
azure_endpoint=os.getenv("API_BASE"),
openai_api_type=os.getenv("API_TYPE"),
openai_api_version=os.getenv("API_VERSION"),
temperature=1, # User to set temperature
)
## 2. Generate responses and confidence scores
WhiteBoxUQ() - Generate LLM responses and compute token-probability-based confidence scores for each response.#

📋 Class Attributes#
Parameter | Type & Default | Description |
|---|---|---|
llm | BaseChatModeldefault=None | A langchain llm |
scorers | List[str]default=None | Specifies which white-box (token-probability-based) scorers to include. Must be subset of {“normalized_probability”, “min_probability”}. If None, defaults to all. |
system_prompt | str or Nonedefault=”You are a helpful assistant.” | Optional argument for user to provide custom system prompt for the LLM. |
max_calls_per_min | intdefault=None | Specifies how many API calls to make per minute to avoid rate limit errors. By default, no limit is specified. |
🔍 Parameter Groups#
🧠 Model-Specific
llm
system_prompt
📊 Confidence Scores
scorers
⚡ Performance
max_calls_per_min
[9]:
wbuq = WhiteBoxUQ(llm=llm)
🔄 Class Methods#
Method | Description & Parameters |
|---|---|
WhiteBoxUQ.generate_and_score | Generate LLM responses and compute confidence scores for the provided prompts. Parameters:
Returns: UQResult containing data (prompts, responses, log probabilities, and confidence scores) and metadata 💡 Best For: Complete end-to-end uncertainty quantification when starting with prompts. |
[10]:
results = await wbuq.generate_and_score(prompts=prompts)
Generating responses...
[11]:
result_df = results.to_df()
result_df.head()
[11]:
| prompt | response | logprob | normalized_probability | min_probability | |
|---|---|---|---|---|---|
| 0 | When you solve this math problem only return t... | 72 | [{'token': '72', 'bytes': [55, 50], 'logprob':... | 0.999949 | 0.999949 |
| 1 | When you solve this math problem only return t... | $10 | [{'token': '$', 'bytes': [36], 'logprob': -0.0... | 0.999398 | 0.998797 |
| 2 | When you solve this math problem only return t... | $20 | [{'token': '$', 'bytes': [36], 'logprob': -0.0... | 0.945383 | 0.900076 |
| 3 | When you solve this math problem only return t... | 48 | [{'token': '48', 'bytes': [52, 56], 'logprob':... | 0.996684 | 0.996684 |
| 4 | When you solve this math problem only return t... | 624 | [{'token': '624', 'bytes': [54, 50, 52], 'logp... | 0.999926 | 0.999926 |
## 3. Evaluate Hallucination Detection Performance
To evaluate hallucination detection performance, we ‘grade’ the responses against an answer key. Note the math_postprocessor is specific to our use case (math questions). If you are using your own prompts/questions, update the grading method accordingly.
[12]:
# Populate correct answers
result_df["answer"] = gsm8k.answer
# Grade responses against correct answers
result_df["response_correct"] = [math_postprocessor(r) == a for r, a in zip(result_df["response"], gsm8k["answer"])]
result_df.head(5)
[12]:
| prompt | response | logprob | normalized_probability | min_probability | answer | response_correct | |
|---|---|---|---|---|---|---|---|
| 0 | When you solve this math problem only return t... | 72 | [{'token': '72', 'bytes': [55, 50], 'logprob':... | 0.999949 | 0.999949 | 72 | True |
| 1 | When you solve this math problem only return t... | $10 | [{'token': '$', 'bytes': [36], 'logprob': -0.0... | 0.999398 | 0.998797 | 10 | True |
| 2 | When you solve this math problem only return t... | $20 | [{'token': '$', 'bytes': [36], 'logprob': -0.0... | 0.945383 | 0.900076 | 5 | False |
| 3 | When you solve this math problem only return t... | 48 | [{'token': '48', 'bytes': [52, 56], 'logprob':... | 0.996684 | 0.996684 | 42 | False |
| 4 | When you solve this math problem only return t... | 624 | [{'token': '624', 'bytes': [54, 50, 52], 'logp... | 0.999926 | 0.999926 | 624 | True |
[13]:
print(f"""Baseline LLM accuracy: {np.mean(result_df["response_correct"])}""")
Baseline LLM accuracy: 0.51
3.1 Filtered LLM Accuracy Evaluation#
Here, we explore ‘filtered accuracy’ as a metric for evaluating the performance of our confidence scores. Filtered accuracy measures the change in LLM performance when responses with confidence scores below a specified threshold are excluded. By adjusting the confidence score threshold, we can observe how the accuracy of the LLM improves as less certain responses are filtered out.
We will plot the filtered accuracy across various confidence score thresholds to visualize the relationship between confidence and LLM accuracy. This analysis helps in understanding the trade-off between response coverage (measured by sample size below) and LLM accuracy, providing insights into the reliability of the LLM’s outputs. We conduct this analysis separately for each of our scorers.
[14]:
for scorer in ["normalized_probability", "min_probability"]:
plot_model_accuracies(scores=result_df[scorer], correct_indicators=result_df.response_correct, title=f"LLM Accuracy by {scorer} Score Threshold")
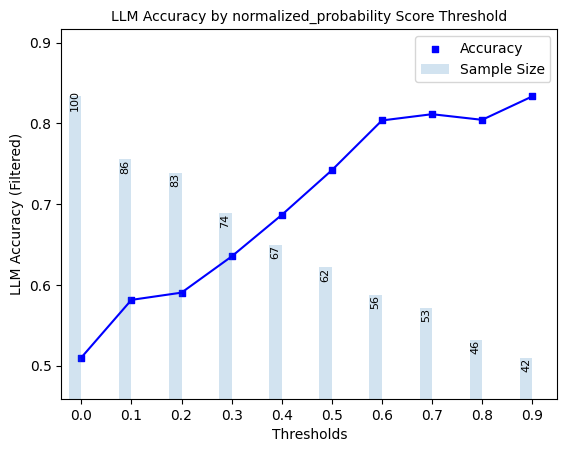
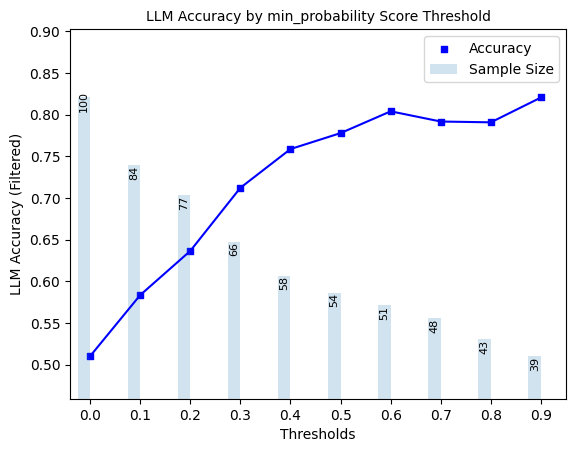
3.2 Precision, Recall, F1-Score of Hallucination Detection#
Lastly, we compute the optimal threshold for binarizing confidence scores, using F1-score as the objective. Using this threshold, we compute precision, recall, and F1-score for black box scorer predictions of whether responses are correct.
[15]:
# instantiate UQLM tuner object for threshold selection
t = Tuner()
correct_indicators = (result_df.response_correct) * 1 # Whether responses is actually correct
for scorer in ["normalized_probability", "min_probability"]:
y_scores = result_df[scorer] # confidence score
# Solve for threshold that maximizes F1-score
best_threshold = t.tune_threshold(y_scores=y_scores, correct_indicators=correct_indicators, thresh_objective="fbeta_score")
y_pred = [(s > best_threshold) * 1 for s in y_scores] # predicts whether response is correct based on confidence score
print(f"{scorer} score F1-optimal threshold: {best_threshold}")
print(" ")
# evaluate precision, recall, and f1-score of predictions of correctness
print(f"{scorer} precision: {precision_score(y_true=correct_indicators, y_pred=y_pred)}")
print(f"{scorer} recall: {recall_score(y_true=correct_indicators, y_pred=y_pred)}")
print(f"{scorer} f1-score: {f1_score(y_true=correct_indicators, y_pred=y_pred)}")
print(" ")
print(" ")
normalized_probability score F1-optimal threshold: 0.5700000000000001
normalized_probability precision: 0.8070175438596491
normalized_probability recall: 0.9019607843137255
normalized_probability f1-score: 0.8518518518518519
min_probability score F1-optimal threshold: 0.51
min_probability precision: 0.8076923076923077
min_probability recall: 0.8235294117647058
min_probability f1-score: 0.8155339805825242
## 4. Scorer Definitions White-box UQ scorers leverage token probabilities of the LLM’s generated response to quantify uncertainty. All scorers have outputs ranging from 0 to 1, with higher values indicating higher confidence. We define two white-box UQ scorers below.
Length-Normalized Token Probability (normalized_probability)#
Let the tokenization LLM response \(y_i\) be denoted as \(\{t_1,...,t_{L_i}\}\), where \(L_i\) denotes the number of tokens the response. Length-normalized token probability (LNTP) computes a length-normalized analog of joint token probability:
- :nbsphinx-math:`begin{equation}
LNTP(y_i) = prod_{t in y_i} p_t^{frac{1}{L_i}},
end{equation}` where \(p_t\) denotes the token probability for token \(t\). Note that this score is equivalent to the geometric mean of token probabilities for response \(y_i\). For more on this scorer, refer to Malinin & Gales, 2021.
Minimum Token Probability (min_probability)#
Minimum token probability (MTP) uses the minimum among token probabilities for a given responses as a confidence score:
- :nbsphinx-math:`begin{equation}
MTP(y_i) = min_{t in y_i} p_t,
end{equation}` where \(t\) and \(p_t\) follow the same definitions as above. For more on this scorer, refer to Manakul et al., 2023.
© 2025 CVS Health and/or one of its affiliates. All rights reserved.