🎯 Long-Text Uncertainty Quantification#
Long-Text Uncertainty Quantification (LUQ) is a long-form adaptation of black-box uncertainty quantification. This approach generates multiple responses to the same prompt, decomposes those responses into granular units (sentences or claims), and scores those units by measuring whether sampled responses entail each unit. This demo provides an illustration of how to use the LUQ methods with uqlm. The available scorers and papers from which they are adapted are below:
Long-text Uncertainty Quantification (LUQ) (Zhang et al., 2024)
LUQ-Atomic (Zhang et al., 2024)
LUQ-pair (Zhang et al., 2024)
Generalized LUQ-pair (Zhang et al., 2024)
📊 What You’ll Do in This Demo#
1
Set up LLM and prompts.
Set up LLM instance and load example data prompts.
2
Generate LLM Responses and Confidence Scores
Generate responses and compute claim-level confidence scores using the LongTextUQ() class.
3
Evaluate Hallucination Detection Performance
Grade claims with FactScoreGrader class and evaluate claim-level hallucination detection.
⚖️ Advantages & Limitations#
Pros
Universal Compatibility: Works with any LLM without requiring token probability access
Fine-Grained Scoring: Score at sentence or claim-level to localize likely hallucinations
Uncertainty-aware decoding: Improve factual precision by dropping high-uncertainty claims
Cons
Higher Cost: Requires multiple generations per prompt
Slower: Multiple generations and comparison calculations increase latency
[1]:
import numpy as np
from uqlm import LongTextUQ
from uqlm.utils import load_example_dataset, display_response_refinement, claims_dicts_to_lists, plot_model_accuracies
from uqlm.longform import FactScoreGrader
1. Set up LLM and Prompts#
In this demo, we will illustrate this approach using the FactScore longform QA dataset. To implement with your use case, simply replace the example prompts with your data.
[2]:
# Load example dataset (FactScore)
factscore = load_example_dataset("factscore", n=20)[["factscore_prompt", "wikipedia_text"]].rename(columns={"factscore_prompt": "prompt"})
factscore.head()
Loading dataset - factscore...
Processing dataset...
Dataset ready!
[2]:
| prompt | wikipedia_text | |
|---|---|---|
| 0 | Tell me a bio of Suthida.\n | Suthida Bajrasudhabimalalakshana (Thai: สมเด็จ... |
| 1 | Tell me a bio of Miguel Ángel Félix Gallardo.\n | Miguel Ángel Félix Gallardo (born January 8, 1... |
| 2 | Tell me a bio of Iggy Azalea.\n | Amethyst Amelia Kelly (born 7 June 1990), know... |
| 3 | Tell me a bio of Fernando da Costa Novaes.\n | Fernando da Costa Novaes (April 6, 1927 – Marc... |
| 4 | Tell me a bio of Jan Zamoyski.\n | Jan Sariusz Zamoyski (Latin: Ioannes Zamoyski ... |
In this example, we use AzureChatOpenAI to instantiate our LLM, but any LangChain Chat Model may be used. Be sure to replace with your LLM of choice.
[3]:
# import sys
# !{sys.executable} -m pip install langchain-openai
## User to populate .env file with API credentials
from dotenv import load_dotenv, find_dotenv
from langchain_openai import AzureChatOpenAI
load_dotenv(find_dotenv())
llm = AzureChatOpenAI(
deployment_name="gpt-4o",
openai_api_type="azure",
openai_api_version="2024-12-01-preview",
temperature=1, # User to set temperature
)
2. Generate LLM Responses and Claim/Sentence-Level Confidence Scores#
LongTextUQ() - Generate long-text LLM responses, decompose into claims or sentences, and measure entailment among sampled responses.#
📋 Class Attributes#
Parameter | Type & Default | Description |
|---|---|---|
llm | BaseChatModeldefault=None | A langchain llm |
granularity | strdefault=”claim” | Specifies whether to decompose and score at claim or sentence level granularity. Must be either “claim” or “sentence”. |
mode | strdefault=”unit_response” | Specifies whether to implement unit-response (LUQ-style) scoring or matched-unit (LUQ-pair-style) scoring. Must be either “unit_response” (recommended) or “matched_unit”. |
scorers | List[str]default=None | Specifies which black box (consistency) scorers to include. subset of {“entailment”, “noncontradiction”, “contrasted_entailment”, “bert_score”, “cosine_sim”}. If None, defaults to [“entailment”]. |
aggregation | strdefault=”mean” | Specifies how to aggregate claim/sentence-level scores to response-level scores. Must be one of ‘min’ or ‘mean’. |
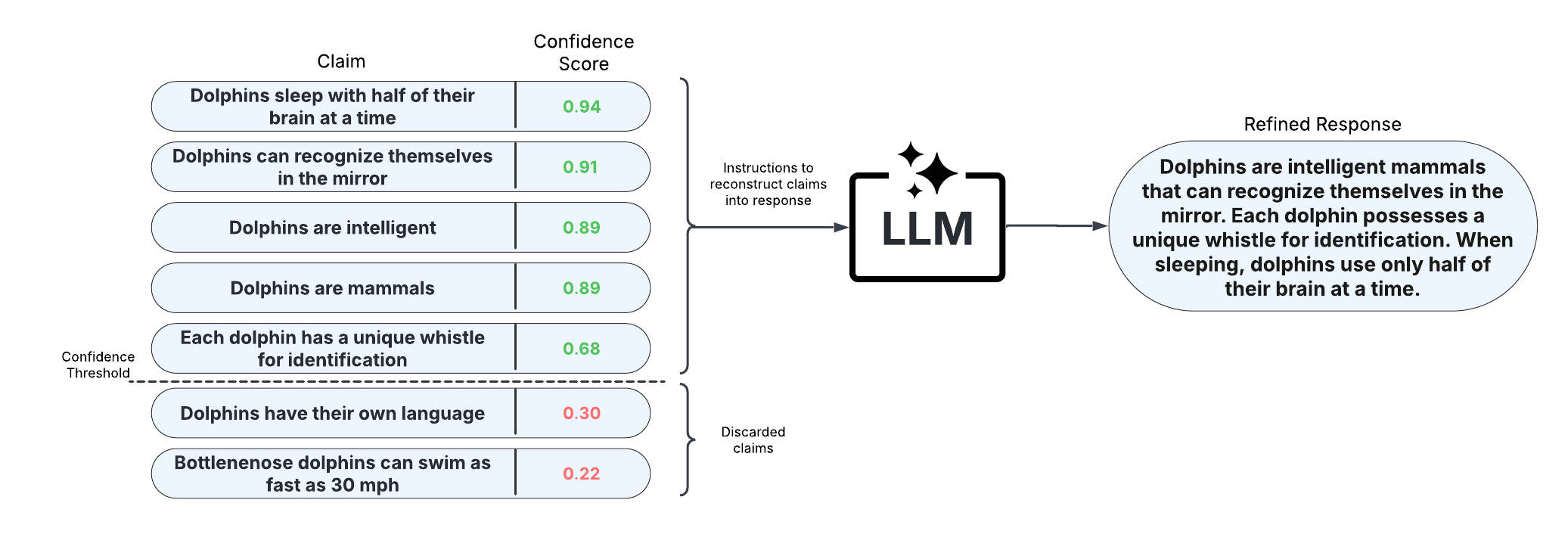
response_refinement | booldefault=False | Specifies whether to refine responses with uncertainty-aware decoding. This approach removes claims with confidence scores below the response_refinement_threshold and uses the claim_decomposition_llm to reconstruct the response from the retained claims. For more details, refer to Jiang et al., 2024: https://arxiv.org/abs/2410.20783 |
claim_filtering_scorer | Optional[str]default=None | Specifies which scorer to use to filter claims if response_refinement is True. If not provided, defaults to the first element of self.scorers. |
claim_decomposition_llm | BaseChatModeldefault=None | A langchain llm |
nli_llm | BaseChatModeldefault=None | A LangChain chat model for LLM-based NLI inference. If provided, takes precedence over nli_model_name. Only used for mode=”unit_response” |
device | str or torch.devicedefault=None | Specifies the device that NLI model use for prediction. If None, detects and returns the best available PyTorch device. Prioritizes CUDA (NVIDIA GPU), then MPS (macOS), then CPU. |
system_prompt | str or Nonedefault=”You are a helpful assistant.” | Optional argument for user to provide custom system prompt for the LLM. |
max_calls_per_min | intdefault=None | Specifies how many API calls to make per minute to avoid rate limit errors. By default, no limit is specified. |
use_n_param | booldefault=False | Specifies whether to use n parameter for BaseChatModel. Not compatible with all BaseChatModel classes. If used, it speeds up the generation process substantially when num_responses is large. |
sampling_temperature | floatdefault=1 | The ‘temperature’ parameter for LLM to use when generating sampled LLM responses. Must be greater than 0. |
nli_model_name | strdefault=”microsoft/deberta-large-mnli” | Specifies which NLI model to use. Must be acceptable input to AutoTokenizer.from_pretrained() and AutoModelForSequenceClassification.from_pretrained(). |
max_length | intdefault=2000 | Specifies the maximum allowed string length for LLM responses for NLI computation. Responses longer than this value will be truncated in NLI computations to avoid OutOfMemoryError. |
🔍 Parameter Groups#
🧠 LLM-Specific
llm
system_prompt
sampling_temperature
claim_decomposition_llm
nli_llm
📊 Confidence Scores
granularity
scorers
mode
aggregation
response_refinement
response_refinement_threshold
🖥️ Hardware
device
⚡ Performance
max_calls_per_min
use_n_param
```
[4]:
luq = LongTextUQ(
llm=llm,
granularity="claim", # 'claim' recommended
aggregation="mean", # switch to 'min' for more conservative scoring
response_refinement=True, # whether to filter out low-confidence claims
max_calls_per_min=80,
max_length=3000,
)
claim_filtering_scorer is not specified for response_refinement. Defaulting to entailment.
🔄 Class Methods#
Method | Description & Parameters |
|---|---|
BlackBoxUQ.generate_and_score | Generate LLM responses, sampled LLM (candidate) responses, and compute confidence scores for the provided prompts. Parameters:
Returns: UQResult containing data (prompts, responses, sampled responses, and confidence scores) and metadata 💡 Best For: Complete end-to-end uncertainty quantification when starting with prompts. |
BlackBoxUQ.score | Compute confidence scores on provided LLM responses. Should only be used if responses and sampled responses are already generated. Parameters:
Returns: UQResult containing data (responses, sampled responses, and confidence scores) and metadata 💡 Best For: Computing uncertainty scores when responses are already generated elsewhere. |
[5]:
results = await luq.generate_and_score(
prompts=factscore.prompt.to_list(),
num_responses=5, # choose num_responses based on cost and latency requirements (higher means better hallucination detection but more cost and latency)
)
[6]:
result_df = results.to_df()
result_df.head(5)
[6]:
| prompt | response | sampled_responses | entailment | claims_data | refined_response | refined_entailment | |
|---|---|---|---|---|---|---|---|
| 0 | Tell me a bio of Suthida.\n | Suthida Bajrasudhabimalalakshana, born on June... | [Suthida Bajrasudhabimalalakshana, commonly kn... | 0.378289 | [{'claim': 'Suthida Bajrasudhabimalalakshana w... | Suthida Bajrasudhabimalalakshana, born on June... | 0.786631 |
| 1 | Tell me a bio of Miguel Ángel Félix Gallardo.\n | Miguel Ángel Félix Gallardo, often referred to... | [Miguel Ángel Félix Gallardo, often referred t... | 0.472164 | [{'claim': 'Miguel Ángel Félix Gallardo is oft... | Miguel Ángel Félix Gallardo, often referred to... | 0.654868 |
| 2 | Tell me a bio of Iggy Azalea.\n | Iggy Azalea, born Amethyst Amelia Kelly on Jun... | [Iggy Azalea, born Amethyst Amelia Kelly on Ju... | 0.468483 | [{'claim': 'Iggy Azalea was born Amethyst Amel... | Iggy Azalea, born Amethyst Amelia Kelly on Jun... | 0.650532 |
| 3 | Tell me a bio of Fernando da Costa Novaes.\n | Fernando da Costa Novaes was a prominent Brazi... | [Fernando da Costa Novaes was a Brazilian orni... | 0.494438 | [{'claim': 'Fernando da Costa Novaes was a pro... | Fernando da Costa Novaes was a highly respecte... | 0.705326 |
| 4 | Tell me a bio of Jan Zamoyski.\n | Jan Zamoyski (1542–1605) was a prominent Polis... | [Jan Zamoyski (1542–1605) was a prominent Poli... | 0.573752 | [{'claim': 'Jan Zamoyski was a Polish nobleman... | Jan Zamoyski, born in 1542 and deceased in 160... | 0.733766 |
Response refinement#
Response refinement works by dropping claims with confidence scores (specified with claim_filtering_scorer) below a specified threshold (specified with response_refinement_threshold) and reconstructing the response from the retained claims.
To illustrate how the response refinement operates, let’s view an example. We first view the fine-grained claim-level data, including the claims in the original response, the claim-level confidence scores, and whether each claim was removed during the response refinement process.
[7]:
# View fine-grained claim data for the first response
result_df.claims_data[0]
[7]:
[{'claim': 'Suthida Bajrasudhabimalalakshana was born on June 3, 1978.',
'removed': False,
'entailment': 0.9548099517822266},
{'claim': 'Suthida Bajrasudhabimalalakshana is the Queen of Thailand.',
'removed': False,
'entailment': 0.909833800792694},
{'claim': 'Suthida Bajrasudhabimalalakshana became queen following her marriage to King Maha Vajiralongkorn on May 1, 2019.',
'removed': False,
'entailment': 0.9487567067146301},
{'claim': 'Suthida Bajrasudhabimalalakshana was known for her service in the Thai military.',
'removed': False,
'entailment': 0.6286507695913315},
{'claim': 'Suthida Bajrasudhabimalalakshana was known for her service in royal security.',
'removed': False,
'entailment': 0.4196613132953644},
{'claim': 'Suthida Bajrasudhabimalalakshana joined the Thai military.',
'removed': False,
'entailment': 0.8370264410972595},
{'claim': 'Suthida Bajrasudhabimalalakshana rose to the rank of General in the Thai military.',
'removed': False,
'entailment': 0.9057967782020568},
{'claim': "Suthida Bajrasudhabimalalakshana's notable role was as the Deputy Commander of the King’s Own Bodyguard Battalion.",
'removed': True,
'entailment': 0.05324118752032518},
{'claim': 'Suthida Bajrasudhabimalalakshana was appointed as the Commander of the Special Operations Unit of the King’s Guard in 2013.',
'removed': True,
'entailment': 0.011244434397667646},
{'claim': 'Suthida Bajrasudhabimalalakshana was made the Commander of the Royal Thai Aide-de-Camp Department.',
'removed': True,
'entailment': 0.0545421352609992},
{'claim': "Suthida Bajrasudhabimalalakshana's service to the royal family began during Vajiralongkorn's time as Crown Prince.",
'removed': True,
'entailment': 0.17842963952571153},
{'claim': 'Suthida Bajrasudhabimalalakshana was appointed as a General in the Royal Thai Army in December 2016.',
'removed': True,
'entailment': 0.20516443867236375},
{'claim': 'Vajiralongkorn ascended to the throne shortly before December 2016.',
'removed': True,
'entailment': 0.0191670348867774},
{'claim': "Queen Suthida's royal name is Her Majesty Queen Suthida Bajrasudhabimalalakshana.",
'removed': False,
'entailment': 0.7257313817739487},
{'claim': "Queen Suthida's royal name was bestowed upon her after marriage.",
'removed': False,
'entailment': 0.7494151771068573},
{'claim': "The marriage and Queen Suthida's subsequent coronation were part of the elaborate royal ceremonies.",
'removed': True,
'entailment': 0.04578750394284725},
{'claim': "The elaborate royal ceremonies solidified Queen Suthida's position as the consort of the reigning monarch.",
'removed': True,
'entailment': 0.09274227768182755},
{'claim': 'Queen Suthida is known for her dignity.',
'removed': True,
'entailment': 0.16823009476065637},
{'claim': 'Queen Suthida is known for her dedication to her roles in royal duties.',
'removed': True,
'entailment': 0.22584835886955262},
{'claim': 'Queen Suthida is known for her dedication to her previous military service.',
'removed': True,
'entailment': 0.04379986636340618},
{'claim': "Queen Suthida's work and public engagements often highlight charitable activities in Thailand.",
'removed': True,
'entailment': 0.05280689503997564},
{'claim': "Queen Suthida's work and public engagements often support various social causes within Thailand.",
'removed': True,
'entailment': 0.09166227281093597}]
We can then visualize the response refinement process for this response using the display_response_refinement. This shows the original response vs. the refined response and identifies which claims were removed due to low confidence.
[8]:
display_response_refinement(original_text=result_df.response[0], claims_data=result_df.claims_data[0], refined_text=result_df.refined_response[0])
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Response Refinement Example
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────
╭─────────────────────────────────────────────── Original Response ───────────────────────────────────────────────╮ │ Suthida Bajrasudhabimalalakshana, born on June 3, 1978, is the Queen of Thailand. She became queen following │ │ her marriage to King Maha Vajiralongkorn (Rama X) on May 1, 2019. │ │ │ │ Before becoming queen, Suthida was known for her service in the Thai military and royal security. She joined │ │ the Thai military, where she eventually rose to the rank of General. Her notable role was as the Deputy │ │ Commander of the King’s Own Bodyguard Battalion. Suthida was also appointed as the Commander of the Special │ │ Operations Unit of the King’s Guard in 2013, and later, she was made the Commander of the Royal Thai │ │ Aide-de-Camp Department. │ │ │ │ Her service to the royal family and her close association with King Vajiralongkorn began during his time as │ │ Crown Prince. Suthida was appointed as a General in the Royal Thai Army in December 2016, shortly after │ │ Vajiralongkorn ascended to the throne. │ │ │ │ Queen Suthida's royal name, bestowed upon her after marriage, is Her Majesty Queen Suthida │ │ Bajrasudhabimalalakshana. The marriage and her subsequent coronation as queen were part of the elaborate royal │ │ ceremonies that solidified her position as the consort of the reigning monarch. │ │ │ │ Queen Suthida is known for her dignity and dedication to her roles both in royal duties and her previous │ │ military service. Her work and public engagements often highlight charitable activities and support for various │ │ social causes within Thailand. │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────── Low-Confidence Claims to be Removed ──────────────────────────────────────╮ │ • Suthida Bajrasudhabimalalakshana's notable role was as the Deputy Commander of the King’s Own Bodyguard │ │ Battalion. │ │ • Suthida Bajrasudhabimalalakshana was appointed as the Commander of the Special Operations Unit of the King’s │ │ Guard in 2013. │ │ • Suthida Bajrasudhabimalalakshana was made the Commander of the Royal Thai Aide-de-Camp Department. │ │ • Suthida Bajrasudhabimalalakshana's service to the royal family began during Vajiralongkorn's time as Crown │ │ Prince. │ │ • Suthida Bajrasudhabimalalakshana was appointed as a General in the Royal Thai Army in December 2016. │ │ • Vajiralongkorn ascended to the throne shortly before December 2016. │ │ • The marriage and Queen Suthida's subsequent coronation were part of the elaborate royal ceremonies. │ │ • The elaborate royal ceremonies solidified Queen Suthida's position as the consort of the reigning monarch. │ │ • Queen Suthida is known for her dignity. │ │ • Queen Suthida is known for her dedication to her roles in royal duties. │ │ • Queen Suthida is known for her dedication to her previous military service. │ │ • Queen Suthida's work and public engagements often highlight charitable activities in Thailand. │ │ • Queen Suthida's work and public engagements often support various social causes within Thailand. │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─────────────────────────────────────────────── Refined Response ────────────────────────────────────────────────╮ │ Suthida Bajrasudhabimalalakshana, born on June 3, 1978, is the Queen of Thailand. She became queen following │ │ her marriage to King Maha Vajiralongkorn on May 1, 2019, and upon marriage, she was bestowed with the royal │ │ name Her Majesty Queen Suthida Bajrasudhabimalalakshana. Before her ascension to the throne, Queen Suthida was │ │ recognized for her dedicated service in the Thai military, where she rose to the rank of General, and in royal │ │ security. Her military career and commitment to royal security played a significant role in her rise to │ │ prominence, ultimately leading to her role as queen. │ ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
3. Evaluate Hallucination Detection Performance#
To evaluate hallucination detection performance, we ‘grade’ the atomic claims in the responses against an answer key. Here, we use UQLM’s out-of-the-box FactScoreGrader, which can be used with LangChain Chat Model. If you are using your own prompts/questions, be sure to update the grading method accordingly.
[9]:
# set up the LLM grader
from langchain_google_vertexai import ChatVertexAI
gemini_flash = ChatVertexAI(model="gemini-2.5-flash")
grader = FactScoreGrader(llm=gemini_flash)
Before grading, we need to have claims formatted in list of lists where each interior list corresponds to a generated response.
[10]:
# Convert claims to list of lists
claims_data_lists = claims_dicts_to_lists(result_df.claims_data.tolist())
[12]:
# grade original responses against the answer key using the grader
result_df["claim_grades"] = await grader.grade_claims(claim_sets=claims_data_lists["claim"], answers=factscore["wikipedia_text"].to_list())
result_df["answer"] = factscore["wikipedia_text"]
result_df.head(5)
[12]:
| prompt | response | sampled_responses | entailment | claims_data | refined_response | refined_entailment | claim_grades | answer | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Tell me a bio of Suthida.\n | Suthida Bajrasudhabimalalakshana, born on June... | [Suthida Bajrasudhabimalalakshana, commonly kn... | 0.378289 | [{'claim': 'Suthida Bajrasudhabimalalakshana w... | Suthida Bajrasudhabimalalakshana, born on June... | 0.786631 | [True, True, False, True, True, True, True, Fa... | Suthida Bajrasudhabimalalakshana (Thai: สมเด็จ... |
| 1 | Tell me a bio of Miguel Ángel Félix Gallardo.\n | Miguel Ángel Félix Gallardo, often referred to... | [Miguel Ángel Félix Gallardo, often referred t... | 0.472164 | [{'claim': 'Miguel Ángel Félix Gallardo is oft... | Miguel Ángel Félix Gallardo, often referred to... | 0.654868 | [True, True, True, True, False, True, True, Tr... | Miguel Ángel Félix Gallardo (born January 8, 1... |
| 2 | Tell me a bio of Iggy Azalea.\n | Iggy Azalea, born Amethyst Amelia Kelly on Jun... | [Iggy Azalea, born Amethyst Amelia Kelly on Ju... | 0.468483 | [{'claim': 'Iggy Azalea was born Amethyst Amel... | Iggy Azalea, born Amethyst Amelia Kelly on Jun... | 0.650532 | [True, True, True, True, False, True, True, Fa... | Amethyst Amelia Kelly (born 7 June 1990), know... |
| 3 | Tell me a bio of Fernando da Costa Novaes.\n | Fernando da Costa Novaes was a prominent Brazi... | [Fernando da Costa Novaes was a Brazilian orni... | 0.494438 | [{'claim': 'Fernando da Costa Novaes was a pro... | Fernando da Costa Novaes was a highly respecte... | 0.705326 | [True, True, True, True, False, True, True, Tr... | Fernando da Costa Novaes (April 6, 1927 – Marc... |
| 4 | Tell me a bio of Jan Zamoyski.\n | Jan Zamoyski (1542–1605) was a prominent Polis... | [Jan Zamoyski (1542–1605) was a prominent Poli... | 0.573752 | [{'claim': 'Jan Zamoyski was a Polish nobleman... | Jan Zamoyski, born in 1542 and deceased in 160... | 0.733766 | [True, True, True, True, True, True, True, Tru... | Jan Sariusz Zamoyski (Latin: Ioannes Zamoyski ... |
[13]:
all_claim_scores, all_claim_grades = [], []
for i in range(len(result_df)):
all_claim_scores.extend(claims_data_lists["entailment"][i])
all_claim_grades.extend(result_df["claim_grades"][i])
print(f"""Baseline LLM accuracy: {np.mean(all_claim_grades)}""")
Baseline LLM accuracy: 0.6737967914438503
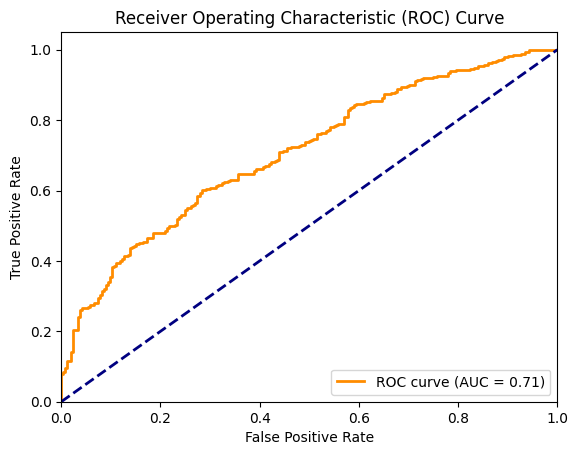
To evaluate fine-grained hallucination detection performance, we compute AUROC of claim-level hallucination detection. Below, we plot the ROC curve and report these results.
[14]:
from sklearn.metrics import roc_curve, roc_auc_score
fpr, tpr, thresholds = roc_curve(y_true=all_claim_grades, y_score=all_claim_scores)
roc_auc = roc_auc_score(y_true=all_claim_grades, y_score=all_claim_scores)
[15]:
import matplotlib.pyplot as plt
plt.figure()
plt.plot(fpr, tpr, color="darkorange", lw=2, label=f"ROC curve (AUC = {roc_auc:.2f})")
plt.plot([0, 1], [0, 1], color="navy", lw=2, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver Operating Characteristic (ROC) Curve")
plt.legend(loc="lower right")
plt.show()
Lastly, we evaluate the gains from uncertainty-aware decoding (UAD) by measuring the factual precision over claims at various filtering thresholds.
[16]:
plot_model_accuracies(scores=all_claim_scores, correct_indicators=all_claim_grades, title="LLM Accuracy by Claim Confidence Threshold", display_percentage=True)
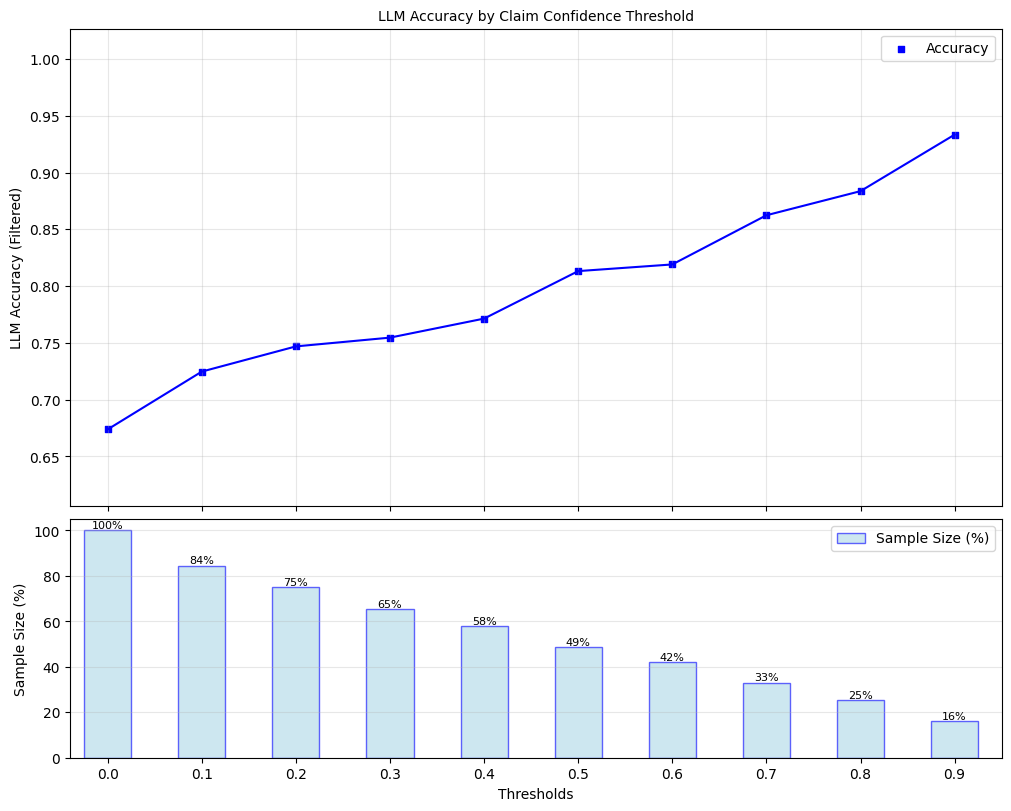
Since, we have selected a threshold of 1/3, we can measure LLM accuracy with and without UAD.
[17]:
thresh = 1 / 3
filtered_grades, filtered_scores = [], []
for grade, score in zip(all_claim_grades, all_claim_scores):
if score > thresh:
filtered_grades.append(grade)
filtered_scores.append(score)
print(f"Baseline LLM factual precision: {np.mean(all_claim_grades)}")
print(f"UAD-Improved LLM factual precision: {np.mean(filtered_grades)}")
Baseline LLM factual precision: 0.6737967914438503
UAD-Improved LLM factual precision: 0.7665952890792291
4. Scorer Definitions#
Long-form uncertainty quantification implements a three-stage pipeline after response generation:
Response Decomposition: The response \(y\) is decomposed into units (claims or sentences), where a unit as denoted as \(s\).
Unit-Level Confidence Scoring: Confidence scores are computed using function \(c_g(s;\cdot) \in [0, 1]\). Higher scores indicate greater likelihood of factual correctness. Units with scores below threshold \(\tau\) are flagged as potential hallucinations.
Response-Level Aggregation: Unit scores are combined to provide an overall response confidence.
The Long-text UQ (LUQ) approach demonstrated here is adapted from Zhang et al., 2024. Similar to standard black-box UQ, this approach requires generating a original response and sampled candidate responses to the same prompt. The original response is then decomposed into units (claims or sentences). Unit-level confidence scores are then obtained by averaging entailment probabilities across candidate responses:
where \(\mathbf{y}^{(s)}_{\text{cand}} = {y_1^{(s)}, ..., y_m^{(s)}}\) are \(m\) candidate responses, and \(P(\text{entail}|y_j, s)\) denotes the NLI-estimated probability that \(s\) is entailed in \(y_j\).
© 2025 CVS Health and/or one of its affiliates. All rights reserved.